
聊天、编程、生成图像、推理 — 全部在 Mac 上本地运行。唯一拥有完整推理引擎、20 多种智能工具、Flux 本地图像生成、语音/视觉/推理的 AI 应用。由 vMLX Engine 驱动。
JANG_Q唯一支持混合精度量化的MLX引擎 — 230B模型2 bits下74% MMLU (82.5 GB) vs MLX 4-bit 26.5% (119.8 GB)
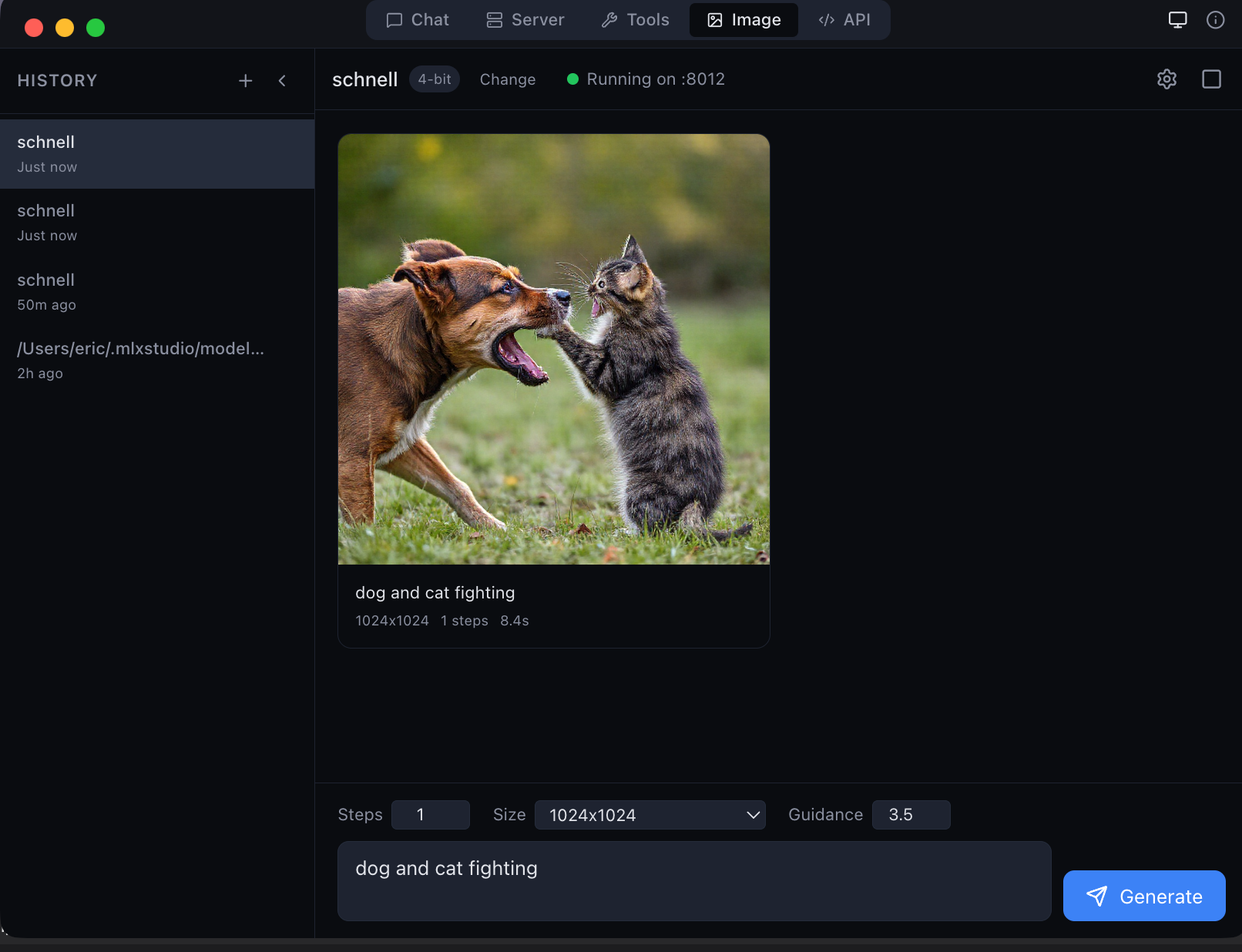
Local image generation with Flux Schnell — 1024×1024 in seconds on Apple Silicon
与任何模型聊天、用 Flux 生成图像、使用 20 多种智能工具编程、使用 Anthropic 或 OpenAI API、在格式之间转换模型 — 全部在 Mac 上本地运行。无需 API 密钥、无需订阅、数据不会离开您的设备。既适合需要简单聊天应用的初学者,也适合需要完整推理栈(KV 缓存量化、前缀缓存、投机解码和 14 个工具解析器)的高级用户。
多轮流式对话,内联工具调用指示器、可折叠推理块、图像预览和实时状态指示器。每个细节都为清晰度精心设计。
在本地生成和编辑图像。5 个生成模型(Flux Schnell、Dev、Klein)+ 4 个编辑模型(Qwen Image Edit、Flux Kontext、Flux Fill)。无需云服务、无需 API 密钥。
每个回复内置文字转语音。使用Mac原生语音合成免提收听AI输出。
将图像拖放到聊天中。Qwen VL等视觉模型在本地分析视觉内容,支持点击放大预览。
适用于DeepSeek R1、Qwen 3和GLM等模型的可折叠思考部分。查看模型的思维链。
原生 Anthropic Messages API 端点以及 OpenAI Chat 和 Responses API。使用 Claude Code、Anthropic SDK 或任何兼容客户端。也可连接远程端点。
内置 GGUF-to-MLX 转换器,支持 标准配置文件(Balanced 4-bit、Quality 8-bit、Compact 3-bit)和 JANG 混合精度配置文件(2S 至 6M)。无需命令行即可转换任何模型。
在应用中直接搜索、浏览和下载MLX模型。一键开始与任何模型聊天。
前缀缓存、分页多上下文KV、KV量化(q4/q8)、连续批处理(256序列)和持久磁盘缓存。没有其他本地应用同时具备这五项功能。
可配置的草稿模型,生成速度提高20–90%。大模型并行验证草稿token — 相同质量,更少GPU传递。
自动检测Llama、Qwen、DeepSeek、Gemma、Mistral、Phi、GLM、Nemotron、MiniMax、Jamba等。14个工具调用解析器、4个推理解析器 — 无需手动配置。
开源引擎。pip install vmlx然后vmlx serve model。从终端转换、基准测试、诊断。Apache 2.0。
内置MCP(Model Context Protocol)服务器。将外部MCP工具与20+内置工具一起连接。代理循环最多自动继续10次迭代。
为Nemotron-H、Jamba和GatedDeltaNet架构提供专用BatchMambaCache。唯一能正确运行混合注意力+SSM模型的本地应用。
唯一支持原生MCP工具调用的本地AI应用。模型可以读取、写入、搜索和执行 — 全部在本地运行。oMLX、LM Studio和Inferencer没有内置智能工具。

5 个图像生成模型(Flux Schnell、Dev、Z-Image Turbo、Klein 4B、Klein 9B)和 4 个图像编辑模型(Qwen Image Edit、Flux Kontext、Flux Fill、Flux Klein Edit)。提交照片和文本提示即可进行修复、变换或风格转换。模型自动下载。无需云 API、无需订阅 — 完全在 Apple Silicon 上运行。

可折叠推理块、内联代码高亮、图像预览和实时token流的多轮对话。为视觉模型拖放图像。每个聊天可设置temperature、top-p、系统提示和最大token数。聊天记录保存在SQLite中。

内置HuggingFace模型浏览器。搜索MLX模型,按文本或图像筛选,查看大小和架构,一键下载。

实时服务器状态、快速模型切换和会话控制 — 始终在菜单栏中一键可达。

在github.com/jjang-ai/vmlx开源 — 使用pip install vmlx安装。Mac上唯一具备5层缓存堆栈的本地AI引擎:前缀缓存、分页KV、KV量化(q4/q8)、连续批处理和持久磁盘缓存。同时提供Anthropic Messages API和OpenAI兼容端点 — 使用Claude Code、Anthropic SDK或任何兼容客户端。50+架构、14个工具解析器、4个推理解析器、Mamba/SSM混合、推测解码。


GGUF为llama.cpp提供了K-quants。JANG为MLX做了同样的事情 — 保护注意力层的智能位分配。 On Qwen3.5-122B at ~2 bits: 94% MMLU (JANG_4K, 69 GB) vs 90% for MLX 4-bit (64 GB). At 2 bits: 84% MMLU (38 GB) vs 46% for MLX mixed_2_6 (44 GB).