
채팅, 코딩, 이미지 생성, 추론 — 모두 Mac에서 로컬로 실행됩니다. 완전한 추론 스택, 20개 이상의 에이전틱 도구, Flux 로컬 이미지 생성, 음성/비전/추론을 갖춘 유일한 AI 앱. vMLX Engine 기반.
JANG_Q혼합 정밀도 양자화를 지원하는 유일한 MLX 엔진 — 230B에서 2 bits로 74% MMLU (82.5 GB) vs MLX 4-bit 26.5% (119.8 GB)
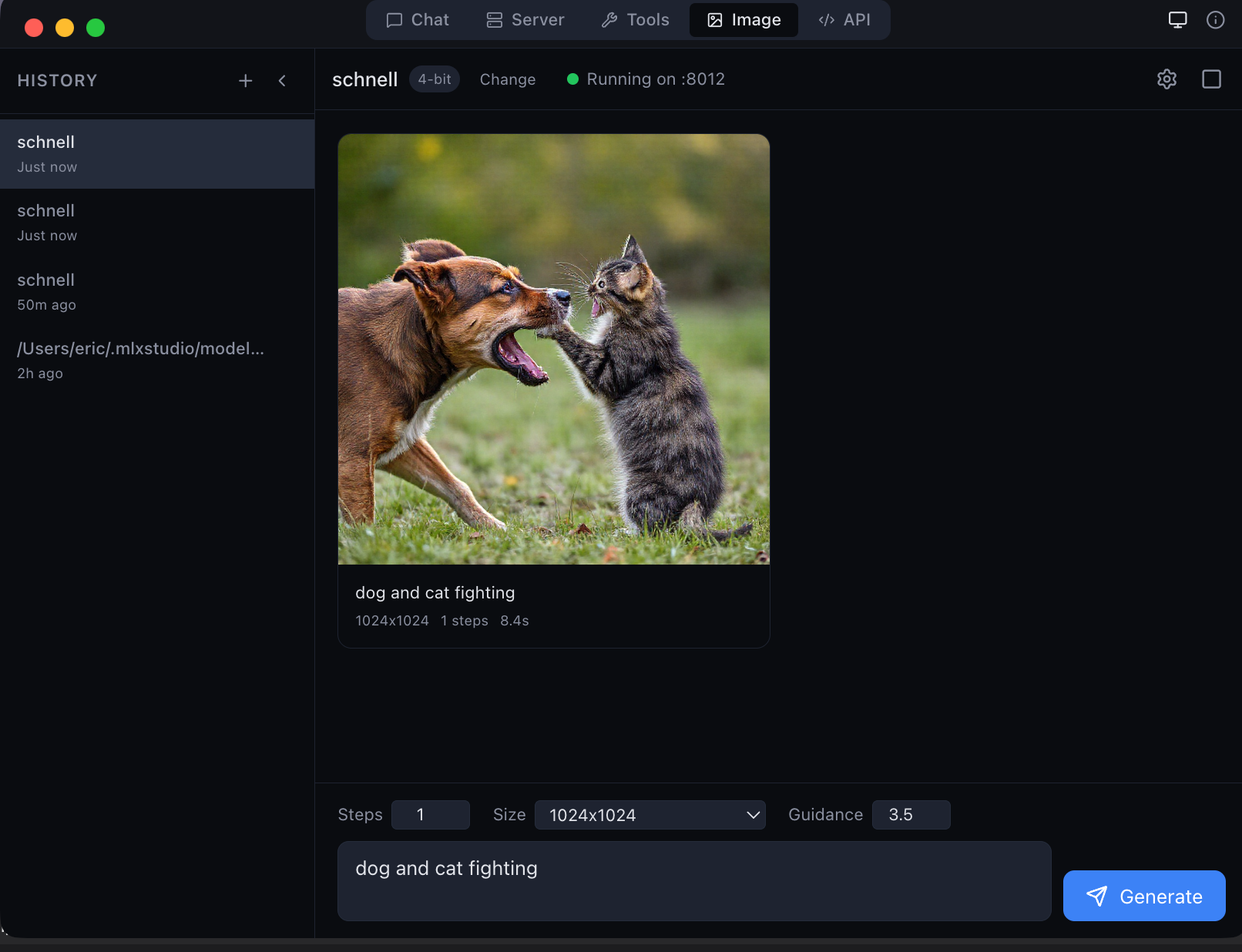
Local image generation with Flux Schnell — 1024×1024 in seconds on Apple Silicon
어떤 모델이든 채팅하고, Flux로 이미지를 생성하고, 20개 이상의 에이전틱 도구로 코딩하고, Anthropic 또는 OpenAI API를 사용하고, 포맷 간 모델을 변환하세요 — 모두 Mac에서 로컬로 실행됩니다. API 키 없음, 구독 없음, 데이터 유출 없음. 간단한 채팅 앱을 원하는 초보자와 KV 캐시 양자화, 프리픽스 캐싱, 추측적 디코딩, 14개 도구 파서를 갖춘 완전한 추론 스택이 필요한 고급 사용자 모두를 위해 제작되었습니다.
멀티턴 스트리밍 대화, 인라인 도구 호출 표시, 접이식 추론 블록, 이미지 미리보기, 실시간 상태 표시. 모든 디테일이 명확하게 설계되었습니다.
로컬에서 이미지를 생성하고 편집하세요. 5개 생성 모델(Flux Schnell, Dev, Klein) + 4개 편집 모델(Qwen Image Edit, Flux Kontext, Flux Fill). 클라우드 없음, API 키 없음.
모든 응답에 내장된 텍스트 음성 변환. Mac 네이티브 음성 합성을 사용하여 핸즈프리로 AI 출력을 들으세요.
이미지를 채팅에 드래그 앤 드롭하세요. Qwen VL 같은 비전 모델이 로컬에서 시각적 콘텐츠를 분석하며, 클릭하여 확대할 수 있습니다.
DeepSeek R1, Qwen 3, GLM 등의 모델을 위한 접이식 사고 섹션. 모델의 사고 과정을 확인하세요.
네이티브 Anthropic Messages API 엔드포인트와 OpenAI Chat 및 Responses API. Claude Code, Anthropic SDK 또는 호환 클라이언트를 사용하세요. 원격 엔드포인트도 연결 가능합니다.
표준 프로필(Balanced 4-bit, Quality 8-bit, Compact 3-bit)과 JANG 혼합 정밀도 프로필(2S~6M)을 지원하는 내장 GGUF-to-MLX 변환기. 커맨드 라인 없이 모든 모델을 변환하세요.
앱에서 직접 MLX 모델을 검색, 탐색, 다운로드하세요. 한 번의 클릭으로 어떤 모델이든 채팅을 시작할 수 있습니다.
프리픽스 캐시, 페이지드 멀티컨텍스트 KV, KV 양자화(q4/q8), 연속 배칭(256 시퀀스), 영구 디스크 캐시. 이 다섯 가지를 모두 결합한 로컬 앱은 없습니다.
설정 가능한 드래프트 모델로 20–90% 더 빠른 생성. 대형 모델이 드래프트 토큰을 병렬로 검증합니다 — 동일한 품질, 더 적은 GPU 패스.
Llama, Qwen, DeepSeek, Gemma, Mistral, Phi, GLM, Nemotron, MiniMax, Jamba 등을 자동 감지합니다. 14개 도구 호출 파서, 4개 추론 파서 — 수동 설정이 필요 없습니다.
오픈 소스 엔진. pip install vmlx 후 vmlx serve model로 실행. 터미널에서 변환, 벤치마크, 진단. Apache 2.0.
내장 MCP(Model Context Protocol) 서버. 20개 이상의 내장 도구와 함께 외부 MCP 도구를 연결하세요. 최대 10회 반복까지 에이전트 루프 자동 계속.
Nemotron-H, Jamba, GatedDeltaNet 아키텍처를 위한 전용 BatchMambaCache. 하이브리드 어텐션 + SSM 모델을 올바르게 실행하는 유일한 로컬 앱.
네이티브 MCP 도구 호출을 지원하는 유일한 로컬 AI 앱. 모델이 읽기, 쓰기, 검색, 실행을 할 수 있으며 — 모두 로컬에서 실행됩니다. oMLX, LM Studio, Inferencer에는 내장 에이전트 도구가 없습니다.

5개의 이미지 생성 모델(Flux Schnell, Dev, Z-Image Turbo, Klein 4B, Klein 9B)과 4개의 이미지 편집 모델(Qwen Image Edit, Flux Kontext, Flux Fill, Flux Klein Edit). 사진과 텍스트 프롬프트를 제출하여 인페인팅, 변환, 스타일 변경이 가능합니다. 모델은 자동으로 다운로드됩니다. 클라우드 API 없음, 구독 없음 — Apple Silicon에서 완전히 실행됩니다.

접이식 추론 블록, 인라인 코드 하이라이팅, 이미지 미리보기, 실시간 토큰 스트리밍이 포함된 멀티턴 대화. 비전 모델용 이미지 드래그 앤 드롭. 채팅별 temperature, top-p, 시스템 프롬프트, 최대 토큰 설정. 채팅 기록은 SQLite에 저장됩니다.

내장 HuggingFace 모델 브라우저. MLX 모델을 검색하고, 텍스트 또는 이미지로 필터링하고, 크기와 아키텍처를 확인하고, 한 번의 클릭으로 다운로드하세요.

실시간 서버 상태, 빠른 모델 전환, 세션 컨트롤 — 메뉴 바에서 항상 한 번의 클릭으로 접근 가능합니다.

github.com/jjang-ai/vmlx에서 오픈 소스로 공개 — pip install vmlx로 설치하세요. Mac에서 5계층 캐싱 스택을 갖춘 유일한 로컬 AI 엔진: 프리픽스 캐시, 페이지드 KV, KV 양자화(q4/q8), 연속 배칭, 영구 디스크 캐시. Anthropic Messages API와 OpenAI 호환 엔드포인트 모두 제공 — Claude Code, Anthropic SDK 또는 호환 클라이언트를 사용하세요. 50+ 아키텍처, 14개 도구 파서, 4개 추론 파서, Mamba/SSM 하이브리드, 추측적 디코딩.


GGUF가 llama.cpp에 K-quants를 제공했습니다. JANG은 MLX에 동일한 역할을 합니다 — 어텐션 레이어를 보호하는 스마트 비트 할당. On Qwen3.5-122B at ~2 bits: 94% MMLU (JANG_4K, 69 GB) vs 90% for MLX 4-bit (64 GB). At 2 bits: 84% MMLU (38 GB) vs 46% for MLX mixed_2_6 (44 GB).