
チャット、コーディング、画像生成、推論 — すべてMacでローカル実行。完全な推論スタック、20以上のエージェンティックツール、Fluxローカル画像生成、音声/ビジョン/推論を備えた唯一のAIアプリ。vMLX Engineで駆動。
JANG_Q混合精度量子化対応の唯一のMLXエンジン — 230Bで2 bitsで74% MMLU (82.5 GB) vs MLX 4-bit 26.5% (119.8 GB)
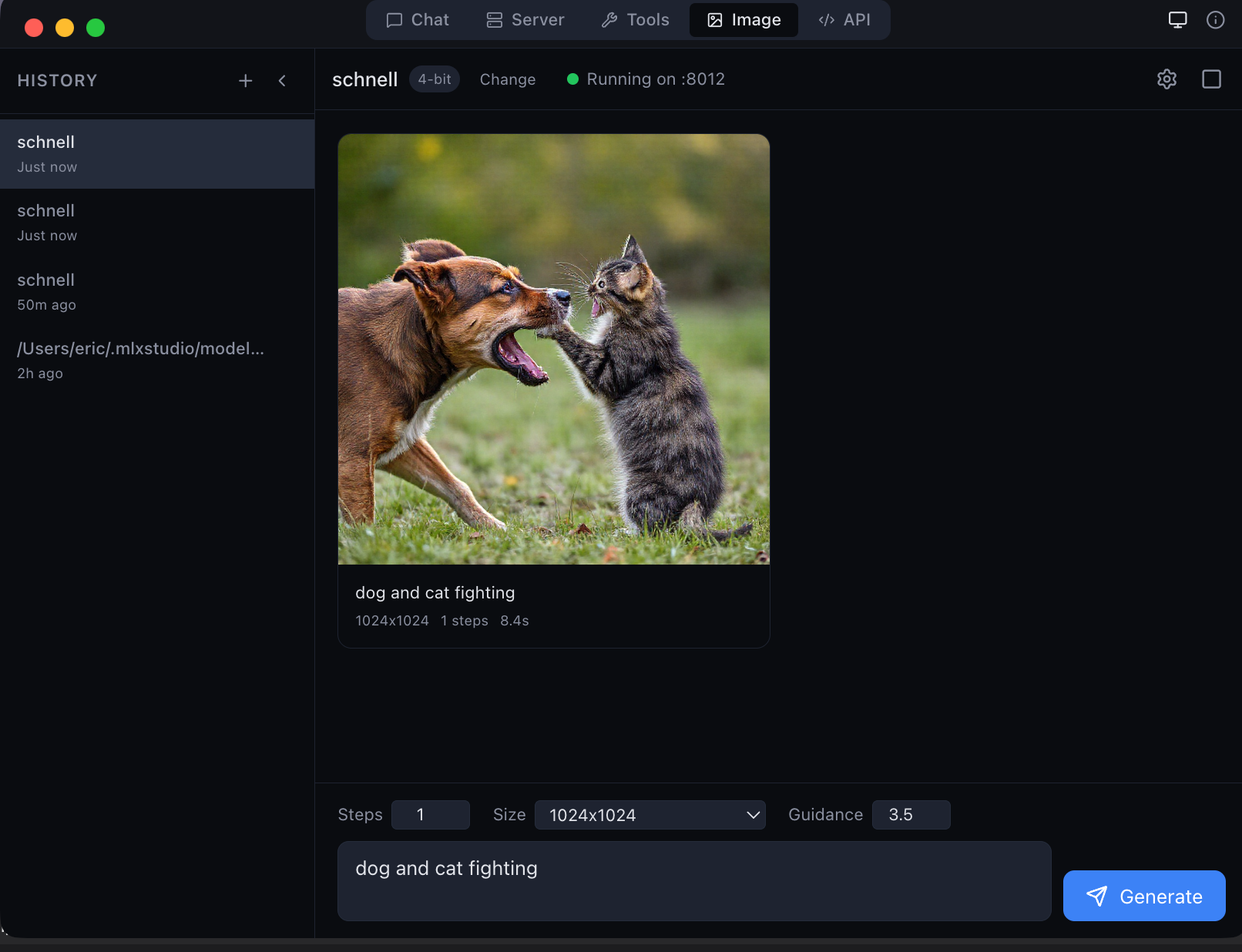
Local image generation with Flux Schnell — 1024×1024 in seconds on Apple Silicon
どんなモデルでもチャットし、Fluxで画像を生成し、20以上のエージェンティックツールでコーディングし、AnthropicまたはOpenAI APIを使用し、フォーマット間でモデルを変換 — すべてMacでローカル実行。APIキー不要、サブスクリプション不要、データ流出なし。シンプルなチャットアプリを求める初心者にも、KVキャッシュ量子化、プレフィックスキャッシュ、投機的デコーディング、14のツールパーサーを備えた完全な推論スタックが必要な上級ユーザーにも対応。
マルチターンストリーミング会話、インラインツール呼び出し表示、折りたたみ可能な推論ブロック、画像プレビュー、リアルタイムステータス表示。すべてのディテールが明確さのために設計されています。
ローカルで画像を生成・編集。5つの生成モデル(Flux Schnell、Dev、Klein)+ 4つの編集モデル(Qwen Image Edit、Flux Kontext、Flux Fill)。クラウド不要、APIキー不要。
すべての応答に内蔵テキスト音声変換。Mac ネイティブ音声合成を使用してハンズフリーでAI出力を聴けます。
画像をチャットにドラッグ&ドロップ。Qwen VLなどのビジョンモデルがローカルで視覚コンテンツを分析し、クリックで拡大できます。
DeepSeek R1、Qwen 3、GLMなどのモデル用の折りたたみ可能な思考セクション。モデルの思考プロセスを確認できます。
ネイティブAnthropic Messages APIエンドポイントとOpenAI ChatおよびResponses API。Claude Code、Anthropic SDK、または互換クライアントを使用できます。リモートエンドポイントにも接続可能。
標準プロファイル(Balanced 4-bit、Quality 8-bit、Compact 3-bit)とJANG混合精度プロファイル(2S〜6M)を備えた内蔵GGUF-to-MLX変換機。コマンドラインなしであらゆるモデルを変換できます。
アプリ内で直接MLXモデルを検索、閲覧、ダウンロード。ワンクリックで任意のモデルとチャットを開始できます。
プリフィックスキャッシュ、ページドマルチコンテキストKV、KV量子化(q4/q8)、連続バッチング(256シーケンス)、永続ディスクキャッシュ。この5つすべてを組み合わせたローカルアプリは他にありません。
設定可能なドラフトモデルで20–90%高速な生成。大規模モデルがドラフトトークンを並列で検証 — 同じ品質、少ないGPUパス。
Llama、Qwen、DeepSeek、Gemma、Mistral、Phi、GLM、Nemotron、MiniMax、Jambaなどを自動検出。14のツール呼び出しパーサー、4つの推論パーサー — 手動設定不要。
オープンソースエンジン。pip install vmlxの後にvmlx serve modelで実行。ターミナルから変換、ベンチマーク、診断。Apache 2.0。
内蔵MCP(Model Context Protocol)サーバー。20以上の内蔵ツールと共に外部MCPツールを接続。最大10回の反復までエージェントループを自動継続。
Nemotron-H、Jamba、GatedDeltaNetアーキテクチャ用の専用BatchMambaCache。ハイブリッドアテンション+SSMモデルを正しく実行する唯一のローカルアプリ。
ネイティブMCPツール呼び出しを備えた唯一のローカルAIアプリ。モデルが読み取り、書き込み、検索、実行できます — すべてローカルで実行。oMLX、LM Studio、Inferencerには内蔵エージェントツールがありません。

5つの画像生成モデル(Flux Schnell、Dev、Z-Image Turbo、Klein 4B、Klein 9B)と4つの画像編集モデル(Qwen Image Edit、Flux Kontext、Flux Fill、Flux Klein Edit)。写真とテキストプロンプトでインペイント、変換、スタイル変更が可能。モデルは自動ダウンロード。クラウドAPI不要、サブスクリプション不要 — Apple Siliconで完全にローカル実行。

折りたたみ可能な推論ブロック、インラインコードハイライト、画像プレビュー、リアルタイムトークンストリーミングを備えたマルチターン会話。ビジョンモデル用の画像ドラッグ&ドロップ。チャットごとのtemperature、top-p、システムプロンプト、最大トークン設定。チャット履歴はSQLiteに保存されます。

内蔵HuggingFaceモデルブラウザ。MLXモデルを検索し、テキストまたは画像でフィルタリングし、サイズとアーキテクチャを確認し、ワンクリックでダウンロード。

リアルタイムサーバーステータス、クイックモデル切り替え、セッションコントロール — メニューバーから常にワンクリックでアクセス可能。

github.com/jjang-ai/vmlxでオープンソースとして公開 — pip install vmlxでインストール。Macで5層キャッシングスタックを備えた唯一のローカルAIエンジン:プリフィックスキャッシュ、ページドKV、KV量子化(q4/q8)、連続バッチング、永続ディスクキャッシュ。Anthropic Messages APIとOpenAI互換エンドポイントの両方を提供 — Claude Code、Anthropic SDK、または互換クライアントを使用。50+アーキテクチャ、14ツールパーサー、4推論パーサー、Mamba/SSMハイブリッド、投機的デコーディング。


GGUFがllama.cppにK-quantsを提供しました。JANGはMLXに同じことをします — アテンションレイヤーを保護するスマートビット割り当て。 On Qwen3.5-122B at ~2 bits: 94% MMLU (JANG_4K, 69 GB) vs 90% for MLX 4-bit (64 GB). At 2 bits: 84% MMLU (38 GB) vs 46% for MLX mixed_2_6 (44 GB).