
Chat, código, generación de imágenes y razonamiento — todo ejecutándose localmente en tu Mac. La única app de IA con un stack de inferencia completo, más de 20 herramientas agénticas, generación local de imágenes con Flux, y voz/visión/razonamiento. Impulsado por vMLX Engine.
JANG_QEl único motor MLX con cuantización de precisión mixta — 74% MMLU en 230B a 2 bits (82.5 GB) vs MLX 4-bit 26.5% (119.8 GB)
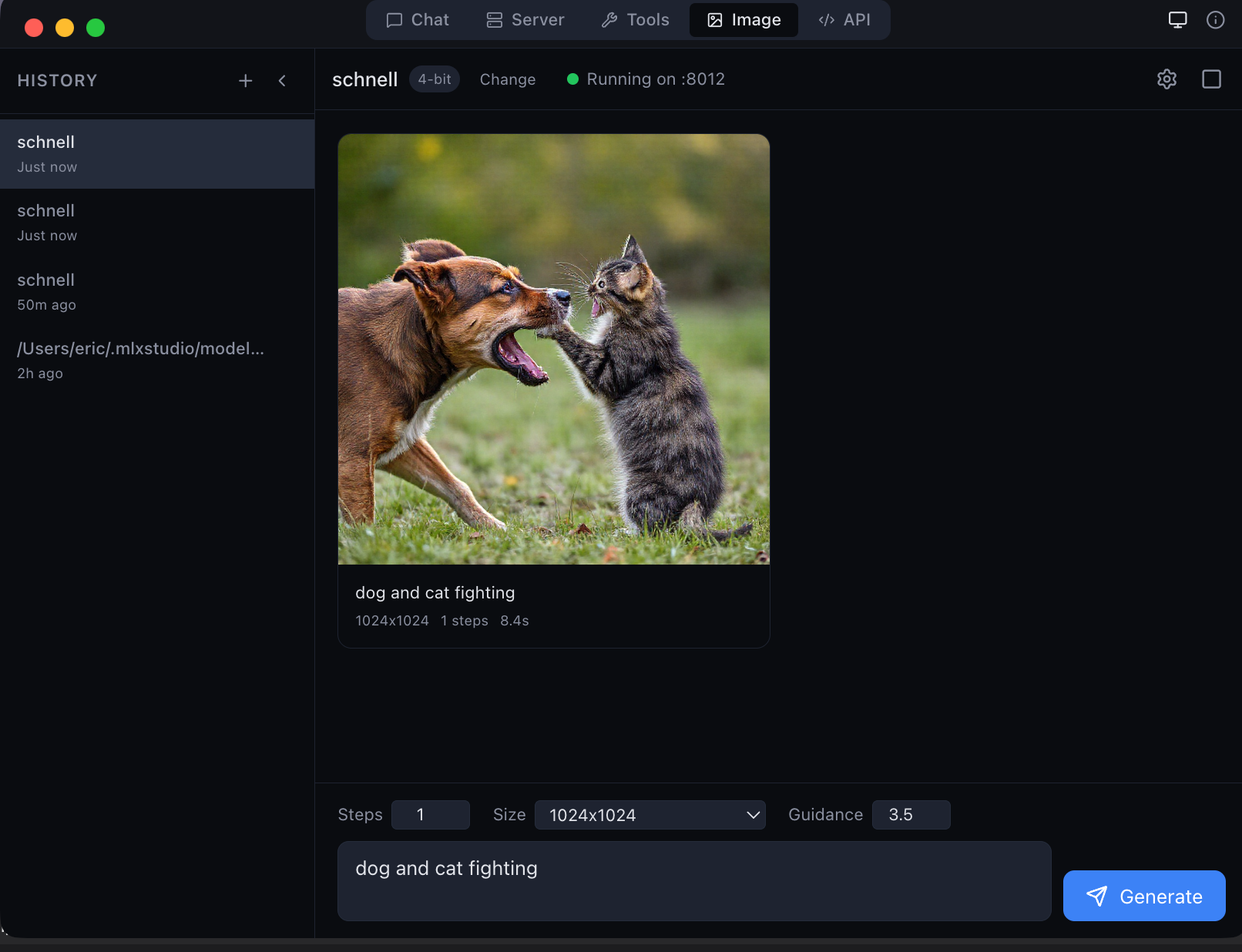
Local image generation with Flux Schnell — 1024×1024 in seconds on Apple Silicon
Chatea con cualquier modelo, genera imágenes con Flux, programa con más de 20 herramientas agénticas, usa APIs de Anthropic u OpenAI, convierte modelos entre formatos — todo ejecutándose localmente en tu Mac. Sin claves API, sin suscripciones, sin datos saliendo de tu máquina. Diseñado tanto para principiantes que quieren una app de chat simple como para usuarios avanzados que necesitan un stack de inferencia completo con cuantización de caché KV, prefix caching, decodificación especulativa y 14 parsers de herramientas.
Conversaciones en streaming multi-turno con indicadores de llamadas a herramientas, bloques de razonamiento plegables, vistas previas de imágenes e indicadores de estado en tiempo real. Cada detalle diseñado para mayor claridad.
Genera y edita imágenes localmente. 5 modelos de generación (Flux Schnell, Dev, Klein) + 4 modelos de edición (Qwen Image Edit, Flux Kontext, Flux Fill). Sin nube, sin claves API.
Texto a voz integrado en cada respuesta. Escucha la salida de IA en modo manos libres con la síntesis de voz nativa de Mac.
Arrastra y suelta imágenes en el chat. Los modelos de visión como Qwen VL analizan contenido visual localmente con vistas previas ampliables.
Secciones de pensamiento plegables para modelos como DeepSeek R1, Qwen 3 y GLM. Observa la cadena de pensamiento del modelo.
Endpoint nativo de Anthropic Messages API junto con OpenAI Chat y Responses APIs. Usa Claude Code, Anthropic SDK o cualquier cliente compatible. También conecta a endpoints remotos.
Convertidor GGUF-to-MLX integrado con perfiles estándar (Balanced 4-bit, Quality 8-bit, Compact 3-bit) y perfiles JANG de precisión mixta (2S a 6M). Convierte cualquier modelo sin la línea de comandos.
Busca, explora y descarga modelos MLX directamente en la app. Un clic para empezar a chatear con cualquier modelo.
Caché de prefijo, KV multi-contexto paginado, cuantización KV (q4/q8), batching continuo (256 secuencias) y caché de disco persistente. Ninguna otra app local combina las cinco.
Modelo borrador configurable para una generación 20–90% más rápida. El modelo grande verifica los tokens borrador en paralelo — misma calidad, menos pasadas de GPU.
Detecta automáticamente Llama, Qwen, DeepSeek, Gemma, Mistral, Phi, GLM, Nemotron, MiniMax, Jamba y más. 14 parsers de llamadas a herramientas, 4 parsers de razonamiento — sin configuración manual.
Motor de código abierto. pip install vmlx luego vmlx serve model. Convierte, benchmarkea, diagnostica desde terminal. Apache 2.0.
Servidor MCP (Model Context Protocol) integrado. Conecta herramientas MCP externas junto con las 20+ herramientas integradas. Continuación automática de bucles de agente hasta 10 iteraciones.
BatchMambaCache dedicado para arquitecturas Nemotron-H, Jamba y GatedDeltaNet. La única app local que ejecuta correctamente modelos híbridos de atención + SSM.
La única app de IA local con llamadas a herramientas MCP nativas. Los modelos pueden leer, escribir, buscar y ejecutar — todo ejecutándose localmente. oMLX, LM Studio e Inferencer no tienen herramientas agénticas integradas.

5 modelos de generación de imágenes (Flux Schnell, Dev, Z-Image Turbo, Klein 4B, Klein 9B) y 4 modelos de edición (Qwen Image Edit, Flux Kontext, Flux Fill, Flux Klein Edit). Envía una foto + prompt de texto para inpaint, transformar o cambiar estilos. Los modelos se descargan automáticamente. Sin APIs en la nube, sin suscripciones — se ejecuta completamente en Apple Silicon.

Conversaciones multi-turno con bloques de razonamiento plegables, resaltado de código en línea, vistas previas de imágenes y streaming de tokens en tiempo real. Arrastra y suelta imágenes para modelos de visión. Temperature, top-p, prompt del sistema y tokens máximos por chat. Historial de chat almacenado en SQLite.

Navegador de modelos HuggingFace integrado. Busca modelos MLX, filtra por texto o imagen, consulta tamaños y arquitecturas, y descarga con un clic.

Estado del servidor en vivo, cambio rápido de modelo y controles de sesión — siempre a un clic en tu barra de menú.

Ahora código abierto en github.com/jjang-ai/vmlx — instala con pip install vmlx. El único motor de IA local en Mac con una pila de caché de 5 capas: caché de prefijo, KV paginado, cuantización KV (q4/q8), batching continuo y caché de disco persistente. Sirve tanto Anthropic Messages API como endpoints compatibles con OpenAI — usa Claude Code, Anthropic SDK o cualquier cliente compatible. 50+ arquitecturas, 14 parsers de herramientas, 4 parsers de razonamiento, híbridos Mamba/SSM, decodificación especulativa.


GGUF le dio a llama.cpp los K-quants. JANG hace lo mismo para MLX — asignación inteligente de bits que protege las capas de atención. On Qwen3.5-122B at ~2 bits: 94% MMLU (JANG_4K, 69 GB) vs 90% for MLX 4-bit (64 GB). At 2 bits: 84% MMLU (38 GB) vs 46% for MLX mixed_2_6 (44 GB).
Descarga MLX Studio y ejecuta IA en tu Mac en menos de 60 segundos.