
Chat, code, generate & edit images, convert models, serve APIs, and reason — all running locally. The only Mac AI app with 20+ agentic tools, Flux image generation + editing (Kontext, Fill, Qwen), Anthropic + OpenAI APIs, JANG & GGUF-to-MLX model converter, 5-layer caching, voice chat, vision models, speculative decoding, and 50+ architectures. No cloud, no API keys, no subscriptions.
JANG_QThe only MLX engine with mixed-precision quantization — 74% MMLU on 230B at 2 bits (82.5 GB) vs MLX 4-bit 26.5% (119.8 GB)
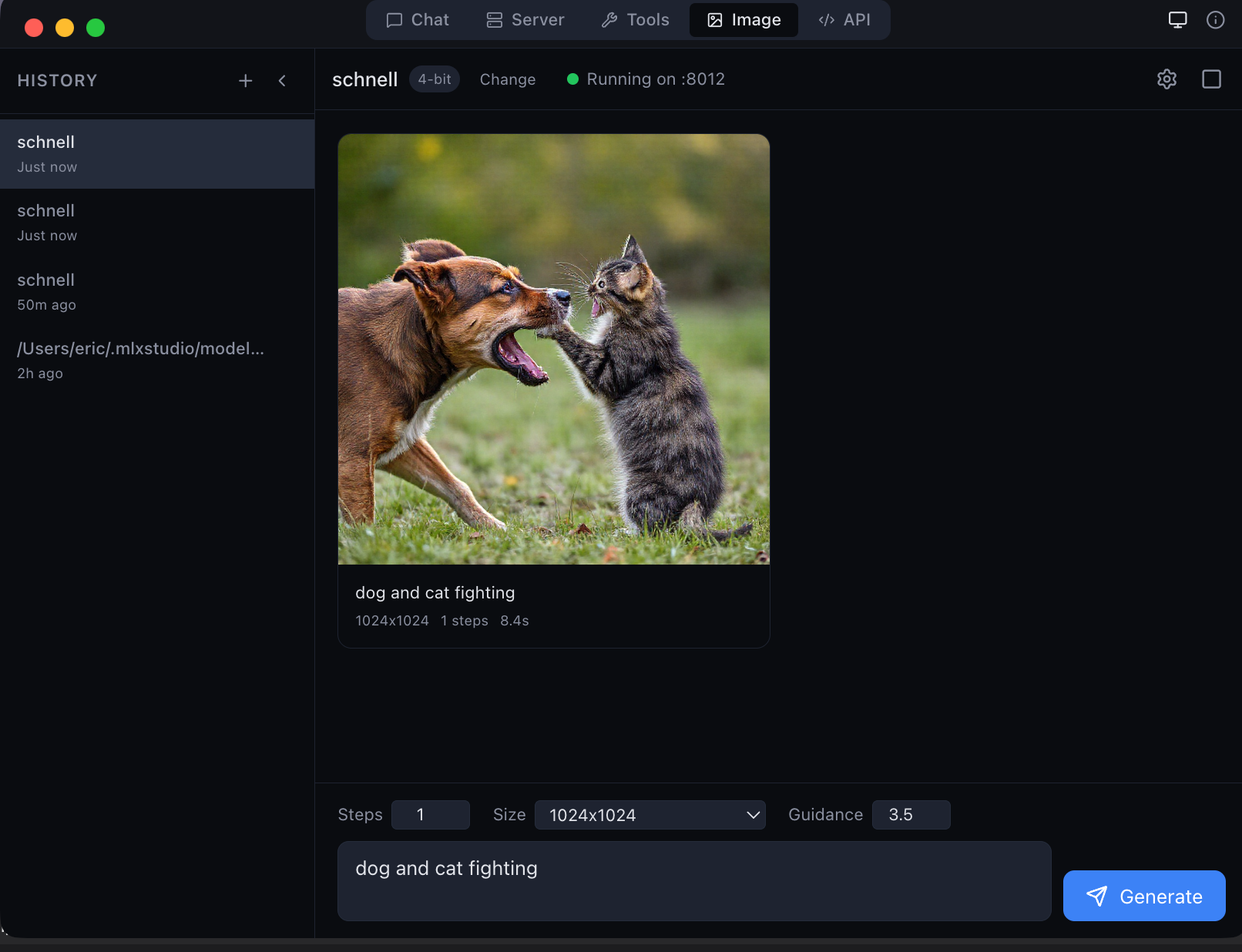
Local image generation with Flux Schnell — 1024×1024 in seconds on Apple Silicon
Chat with any model, generate images with Flux, write code with 20+ agentic tools, use Anthropic or OpenAI APIs, convert models between formats — all running locally on your Mac. No API keys, no subscriptions, no data leaving your machine. Built for beginners who want a simple chat app and advanced users who need a full inference stack with KV cache quantization, prefix caching, speculative decoding, and 14 tool parsers.
Multi-turn streaming conversations with inline tool call pills, collapsible reasoning blocks, image previews, and real-time status indicators. Every detail crafted for clarity.
Generate and edit images locally. 5 generation models (Flux Schnell, Dev, Klein) + 4 editing models (Qwen Image Edit, Flux Kontext, Flux Fill). No cloud, no API keys.
Built-in text-to-speech on every response. Listen to AI output hands-free using native Mac speech synthesis.
Drag and drop images into chat. Vision models like Qwen VL analyze visual content locally with click-to-zoom previews.
Collapsible thinking sections for models like DeepSeek R1, Qwen 3, and GLM. See the model's chain of thought.
Native Anthropic Messages API endpoint alongside OpenAI Chat and Responses APIs. Use Claude Code, OpenClaw, Anthropic SDK, or any compatible client. Connect to remote endpoints too.
Built-in GGUF-to-MLX converter with standard profiles (Balanced 4-bit, Quality 8-bit, Compact 3-bit) and JANG mixed-precision profiles (2S through 6M). Convert any model without the command line.
Search, browse, and download MLX models directly in the app. One click to start chatting with any model.
Prefix cache, paged multi-context KV, KV quantization (q4/q8), continuous batching (256 sequences), and persistent disk cache. No other local app combines all five.
Configurable draft model for 20–90% faster generation. The large model verifies draft tokens in parallel — same quality, fewer GPU passes.
Auto-detects Llama, Qwen, DeepSeek, Gemma, Mistral, Phi, GLM, Nemotron, MiniMax, Jamba, and more. 14 tool call parsers, 4 reasoning parsers — no manual configuration.
Open-source engine. pip install vmlx then vmlx serve model. Convert, benchmark, diagnose from terminal. Apache 2.0.
Built-in MCP (Model Context Protocol) server. Connect external MCP tools alongside the 20+ built-in tools. Auto-continue agent loops up to 10 iterations.
Dedicated BatchMambaCache for Nemotron-H, Jamba, and GatedDeltaNet architectures. The only local app that runs hybrid attention + SSM models correctly.
The only local AI app with native MCP tool calling. Models can read, write, search, and execute — all running locally. oMLX, LM Studio, and Inferencer have no built-in agentic tools.

5 image generation models (Flux Schnell, Dev, Z-Image Turbo, Klein 4B, Klein 9B) and 4 image editing models (Qwen Image Edit, Flux Kontext, Flux Fill, Flux Klein Edit). Submit a photo + text prompt to inpaint, transform, or restyle. Models download automatically. No cloud APIs, no subscriptions — runs entirely on Apple Silicon.

Multi-turn conversations with collapsible reasoning blocks, inline code highlighting, image previews, and real-time token streaming. Drag and drop images for vision models. Per-chat temperature, top-p, system prompt, and max tokens. Chat history persisted in SQLite.

Built-in HuggingFace model browser. Search MLX models, filter by text or image, see sizes and architectures, and download with one click. Pre-quantized JANG models from JANGQ-AI ready to run.

Live server status, quick model switching, and session controls — always one click away in your menu bar. Start/stop models, check GPU usage, and manage sessions without opening the main window.

Now open source at github.com/jjang-ai/vmlx — install with pip install vmlx. The only local AI engine on Mac with a 5-layer caching stack: prefix cache, paged KV, KV quantization (q4/q8), continuous batching, and persistent disk cache. Serves both Anthropic Messages API and OpenAI-compatible endpoints — use Claude Code, OpenClaw, Anthropic SDK, or any compatible client. 50+ architectures, 14 tool parsers, 4 reasoning parsers, Mamba/SSM hybrids, speculative decoding.


GGUF gave llama.cpp K-quants. JANG does the same for MLX — smart bit allocation that protects attention layers. On Qwen3.5-122B: 94% MMLU (JANG_4K, 69 GB) vs 90% for MLX 4-bit (64 GB). At 2 bits: 84% MMLU (38 GB) vs 46% for MLX mixed_2_6 (44 GB).
Download MLX Studio and run AI on your Mac in under 60 seconds.